시차
시간적 차이는 매우 중요한 주제입니다.
시간적 차이는 Q-Learning 알고리즘에서 모두 동일합니다.
결정적 / 비결정적 검색
결정적 검색과 비결정적 검색의 내용을 살펴보겠습니다.
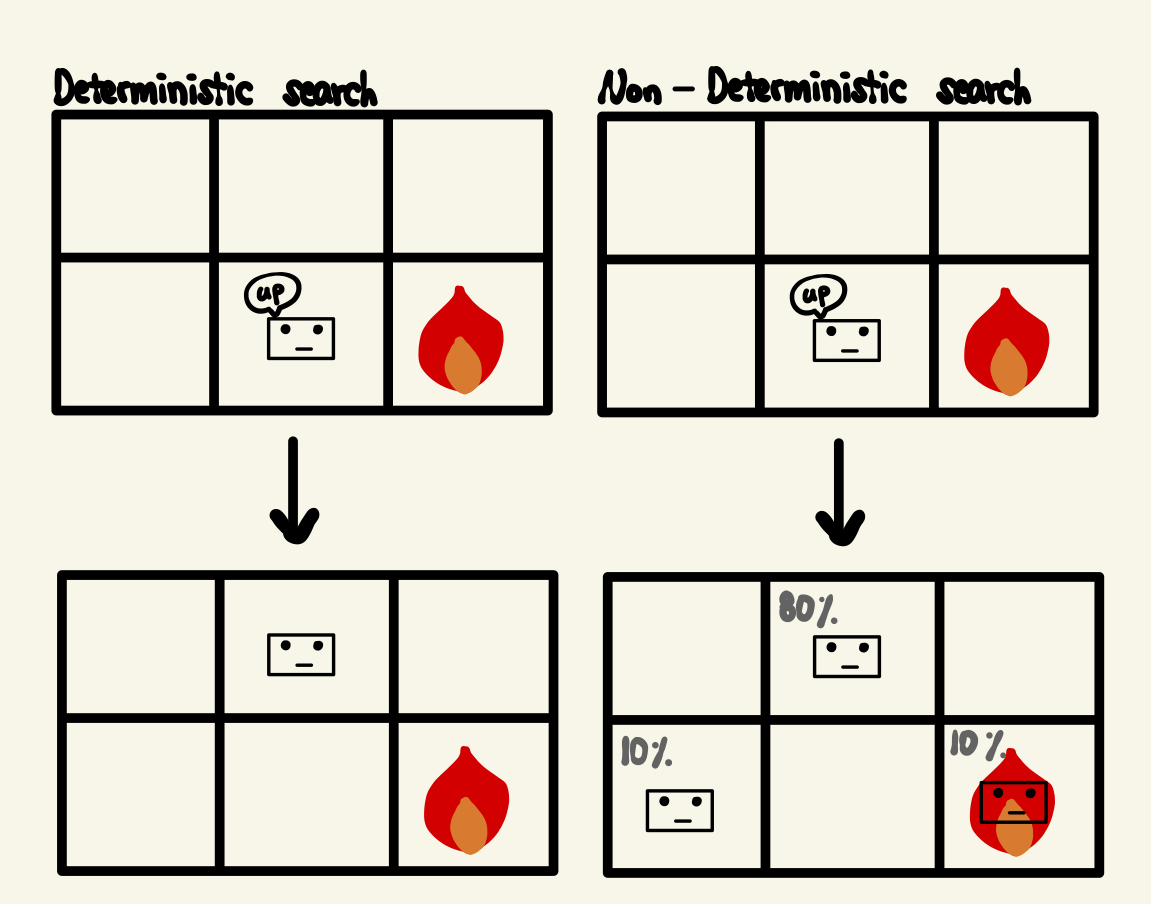
결정론적 탐색의 경우 에이전트가 위로 올라가는 동작을 수행하면 100% 확률로 상위 상태로 이동한다.
반면 비결정적 탐색의 경우 에이전트가 올라가고 싶어도 각각 10% 확률로 다른 상태가 된다.
“에이전트가 제어할 수 없는 임의의 환경에서 비결정적 검색을 시도”해야 합니다. 알고있다
그 결과 결정론적 탐색에서는 상태의 값을 쉽게 계산할 수 있는 반면 비결정적 탐색에서는 정확한 값을 계산하기 어렵다.
(결정적 검색에서는 손으로 계산할 수도 있습니다!!)
“구하는 것은 너무 복잡하지만 컴퓨터는 구하는 것이 쉽습니다.”라고 말한 것을 기억합니다.
이제 정확히 무슨 일이 일어났는지 이해하기 위해 이것을 다시 살펴봅시다.
이전에 비결정적 검색을 처음 배울 때 계산된 미로를 꺼냈습니다.
각 값이 어떻게 계산되는지는 아직 생각하지 맙시다.
다음 그림에서 V = 0.86 열을 살펴보겠습니다.
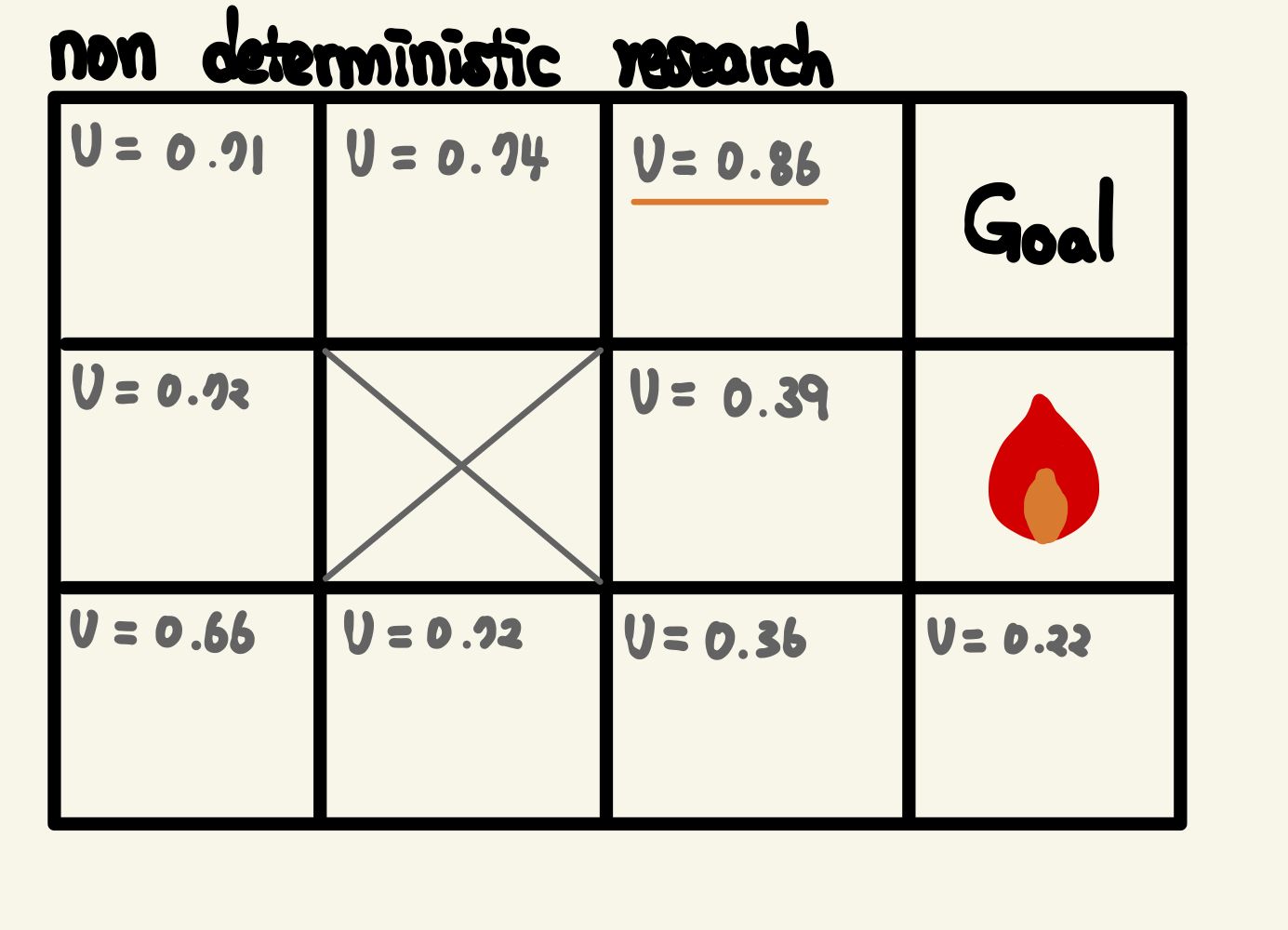
V=0.86의 값을 계산하려고 하면, 주변 셀의 값 값이 필요했습니다.
예를 들어 아래 셀의 값을 계산하려고 합니다.
아래 셀의 값을 계산하려고 했을 때,
그런 다음 위 열의 값을 다시 알아야 할 경우 이를 계산할 수 있습니다.
이 반복이 계속되기 때문에 값을 정확하게 결정할 수 없습니다.
여기에서 시차에이전트가 이 값을 계산할 수 있도록 필드 개념을 추가합니다.
이제 Q에 대해 배웠으니 값을 판단할 때 기준으로 사용하겠습니다.
Q-Bellman 방정식은 다음과 같습니다.
$$ Q(s,a) = R(s,a) + \gamma \sum_{s^\prime} (P(s,a,s^\prime) \underset {a^\prime} {max} { Q(s^\프라임,a^\프라임)}) $$
결정론적 탐색이라면 Q-Bellman 방정식은 다음과 같을 것입니다.
$$ Q(s,a) = R(s,a) + \gamma \underset {a^\prime} {max} Q(s^\prime,a^\prime) $$
로 표기할 수 있다
이전 포스팅에서도 리뷰했지만 다시 유도해보도록 하겠습니다.

앞으로는 편의상 Deterministic이라는 표현을 사용하도록 하겠습니다.
Q값과 시간차를 사용하는 이유
생각 해봐
Q를 사용해야 합니까? Q와 V는 같은 뜻인데 Q를 사용하면 어떤 이점이 있을까요?
아래 사진을 한번 볼까요?
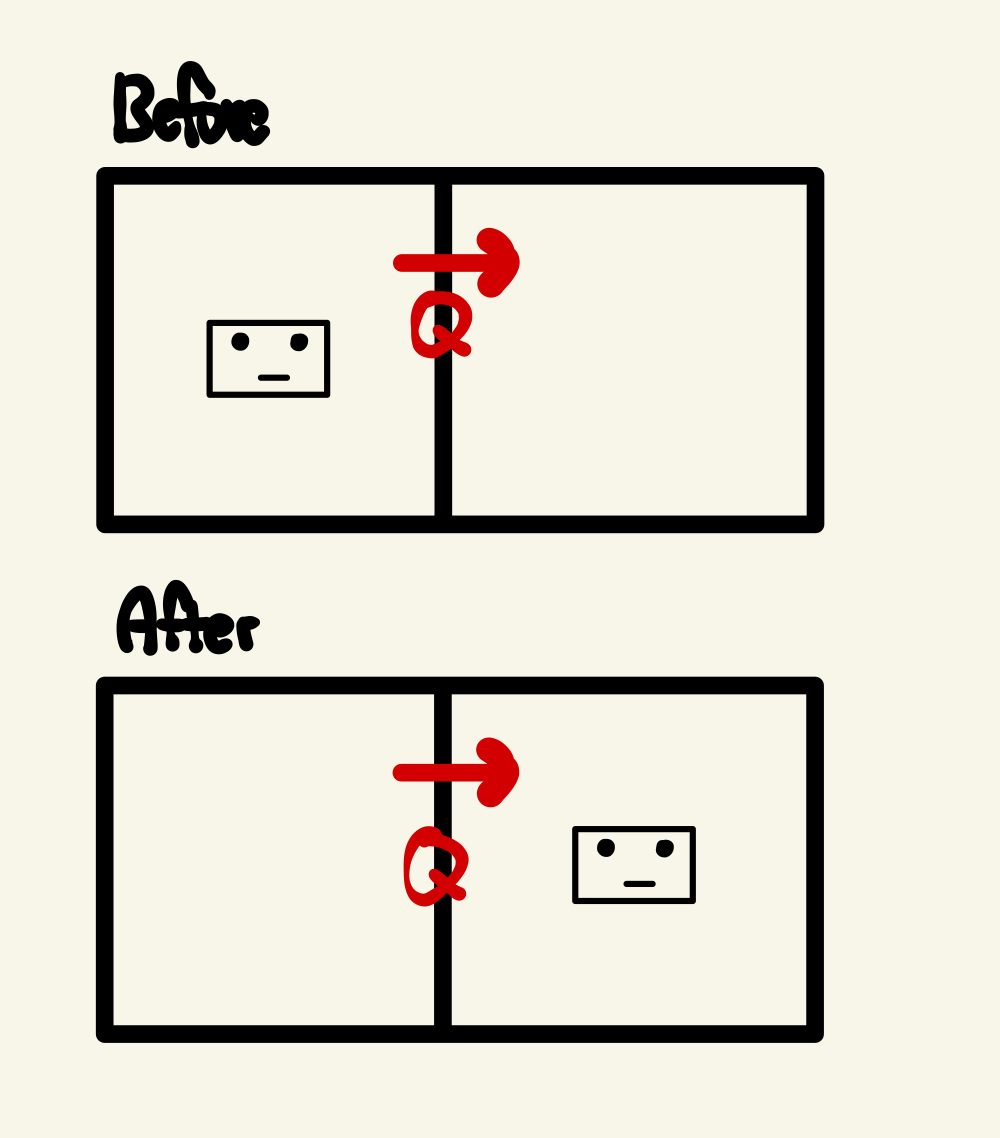
제 개인적인 생각입니다,
어떤 상태의 가치보다 어떤 행동의 가치를 판단한다면 각 상태 사이에 더 많이 느끼기 때문에 각 상태를 따로따로 생각할 수 있다??
일단 제 머릿속 생각은 이렇습니다만, 자세한 설명을 적어보겠습니다.
위 그림의 Agent가 다음과 같은 상황에 있다고 가정해 봅시다.
이제 에이전트가 조치를 취하기 전에 미리 얻은 Q 값으로 조치를 수행합니다.
실제로 행동을 했다면 실제 행동을 하기 전에 Q를 얼마나 아꼈는지 피드백을 줄 수 있습니다.
어떻게 피드백을 주나요?? 이제 실제 행동에서 실제로 가치를 얻었기 때문입니다!!
위의 개념을 정리해 보자.
1. 행동 전에 미리 얻은 가치 Q: $ Q(s,a) $
2. 행동 후, 한 입 먹고 Q 값을 알아내십시오: $ R(s,a) + \gamma \underset{a^\prime} {max} Q(s^\prime,a^ 프라임) $
이상적인 경우에는 두 방정식 사이에 차이가 없습니다.
그러나 실제로는 차이가 있습니다
저도 처음 배우는 입장에서 일종의 수치적 오류라고 생각했습니다.
따라서 두 개념의 차이를 시간차로 정의한다.
$$ TD(s,a) = R(s,a) + \gamma \underset{a^\prime} {max} Q(s^\prime,a^\prime) – Q(s,a) $$
다음 Q 용어는 일부 과거 경험에서 가져온 것입니다.
그럼 여기서 질문이 생길 수 있습니다
“아니, 마르코프 의사 결정 과정은 과거에 영향을 받지 않아서 아쉬워?”
현재 내 대답은 “행동의 선택은 과거에 영향을 받지 않고 현재 상태에서 계산된 Q 값에 의해 결정됩니다…”입니다.
나는 그것을 방어할 것이라고 생각하지만 누군가 더 좋은 아이디어가 있다면 당신의 의견을 듣고 싶습니다.
사용하는 방법
$$ TD(s,a) = R(s,a) + \gamma \underset{a^\prime} {max} Q(s^\prime,a^\prime) – Q(s,a) $$
어디에서 사용할 수 있습니까?
결론은 Q(s,a)의 실제 값을 계산하는 과정에서 사용됩니다.
다음 공식으로 Q 값을 업데이트합니다.
$$ Q(s,a) = Q(s,a) + \alpha TD(a,s) $$
여기서 $ \alpha $는 학습률입니다.
$ \alpha $가 1이면,
이전 Q 값만 지웁니다.
이것은 매우 부적절합니다.
액션이 랜덤하게 발생하기 때문에 10% 또는 20% 확률로 랜덤하게 발생하는 액션은
전체를 나타내는 효과가 있기 때문입니다.
마찬가지로 0이면 전혀 학습하지 않습니다.
하지만 0~1 사이의 적절한 학습률을 적용하면 일정한 값으로 수렴하게 됩니다.
즉, TD 값이 점차 0으로 수렴한다는 의미입니다.